Querying SPARQL
Querying Linked Data using SPARQL
SPARQL is a powerful and generic API to query data on the web or your Intranet. In this post, we want to show how you can query CSV, JSON, or XML from any SPARQL endpoint and point you to SPARQL libraries in various programming languages.
Besides result set answers, SPARQL can return RDF subgraphs as well. This is not covered here. If you are looking for more general information on SPARQL, check out the last two sections of this post.
SPARQL web frontends
When you (or someone else) creates a SPARQL query you likely use an HTML-based frontend with a nice editor that provides SPARQL syntax highlighting and previews for what you do. An example of that is the Wikidata Query Service (opens new window) or the LINDAS (opens new window) SPARQL endpoint from the Swiss government. This is the recommended way to work on your queries, at least initially. It helps you find syntax errors and provides nice plugins. In the example below (opens new window) we use a plugin that can represent well-known-text strings for geospatial data directly on the map. In this particular example, we combine data from ElCom (opens new window) with spatial data from Swisstopo (opens new window) to display Swiss energy providers on a map.
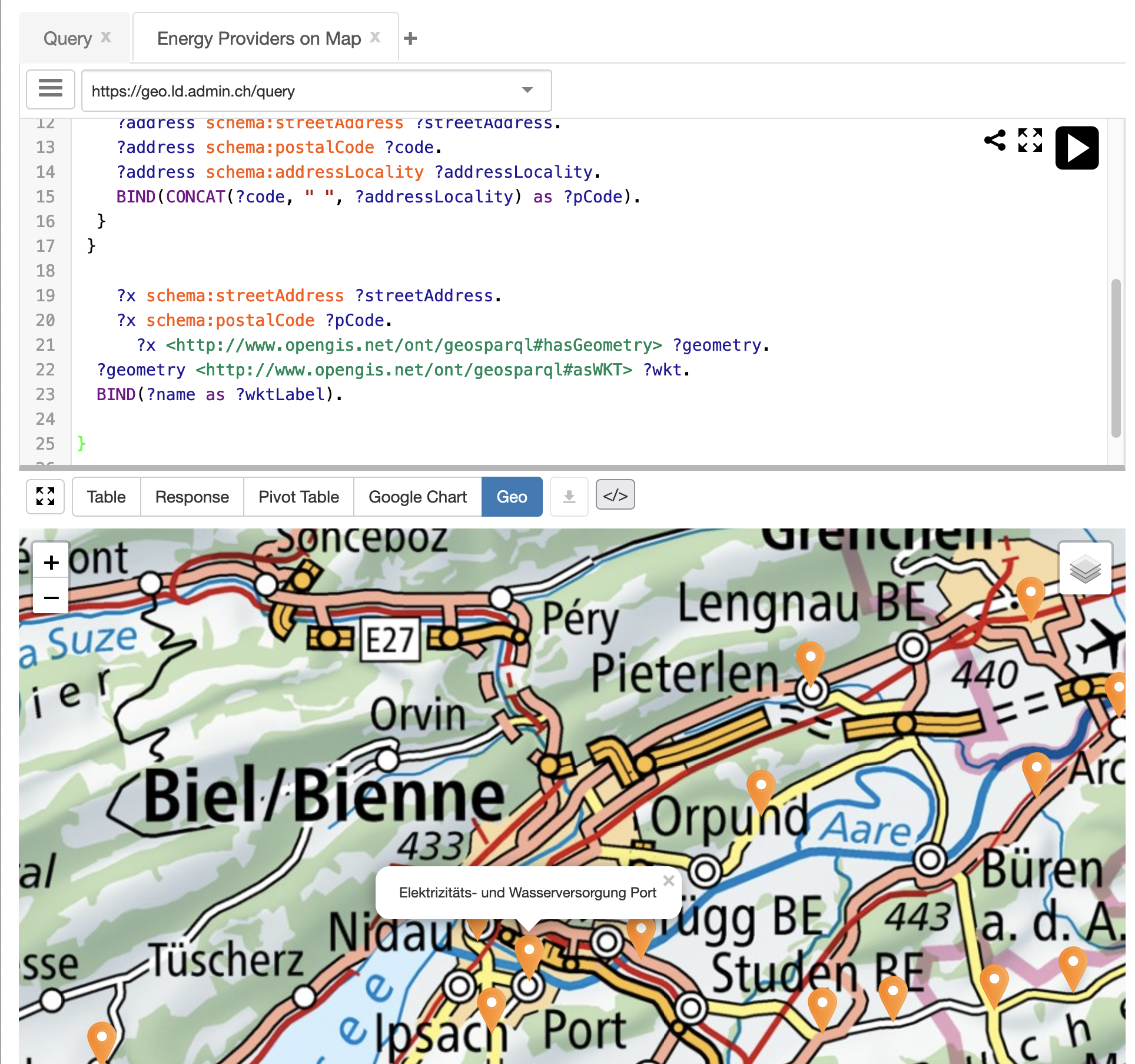
Once you finished the query, the easiest way to share it with others is to get a link that encodes the query in an URL. Most frontends provide this functionality, in YASGUI (opens new window) for example, this is the share button:
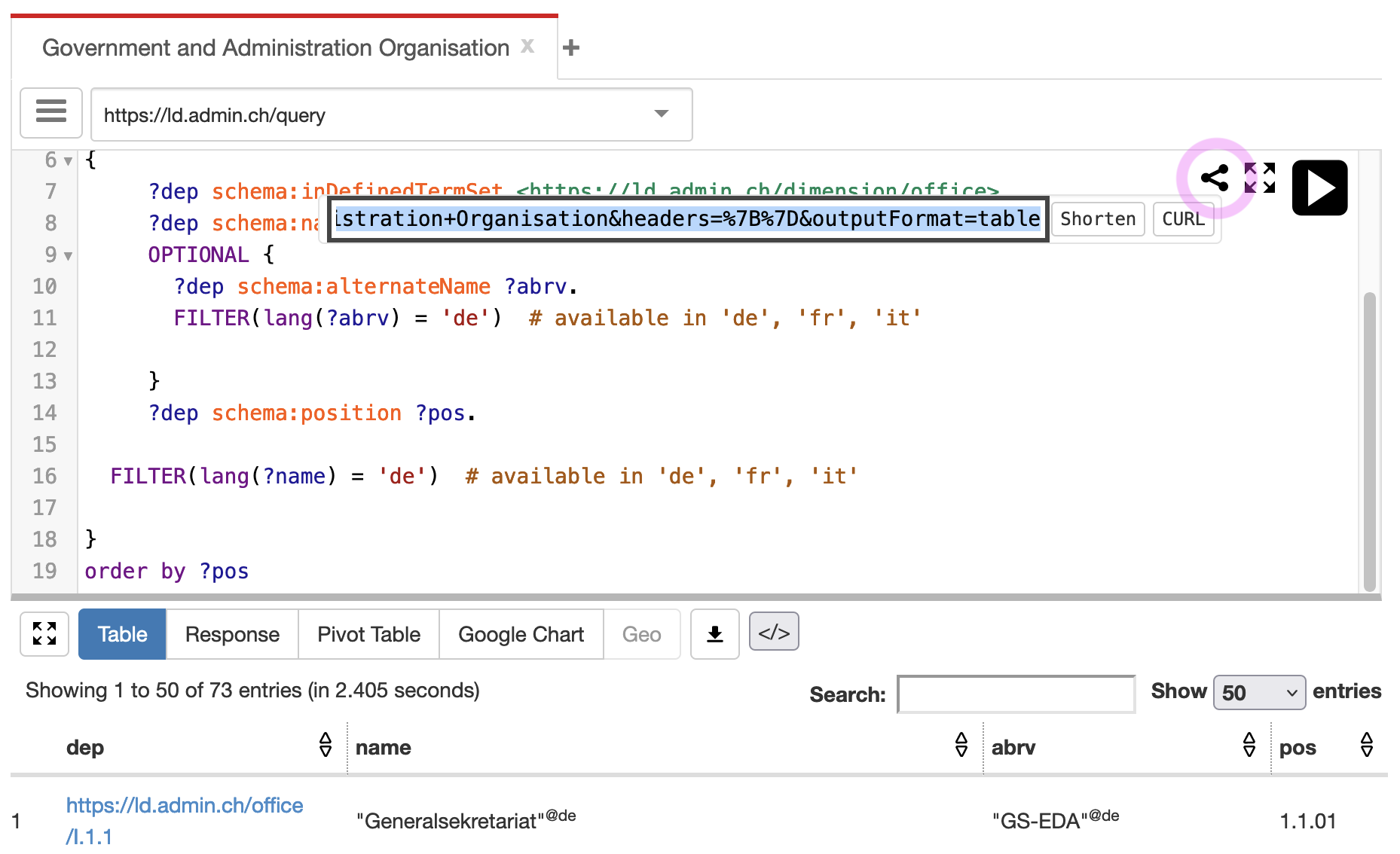
This returns a long version of the query which is simply using encodeURI (opens new window) to serialize the string in the URL. Some services provide a built-in URL shortener so it's easier to pass around.
This is all great as long as you just want to share the query with other people. For machines, this is not the way you want to access the data.
Using curl
There are many ways how you can query a SPARQL endpoint with curl. Bob DuCharme, the author of Learning SPARQL, has a more detailed blog with some background here (opens new window).
In the end, either you or curl needs to:
- URL-encode the query
- Send it to the right endpoint
- Request a specific content-type (unless you are happy with whatever the default is)
The right endpoint
In most setups, there is a catch: The HTML frontend is not the SPARQL query endpoint. In other words curl, a library, or even your SPARQL frontend send the query to the SPARQL endpoint itself. This endpoint is simply a dedicated route on the webserver that speaks the SPARQL 1.1 Protocol. In the example before, this is this part:
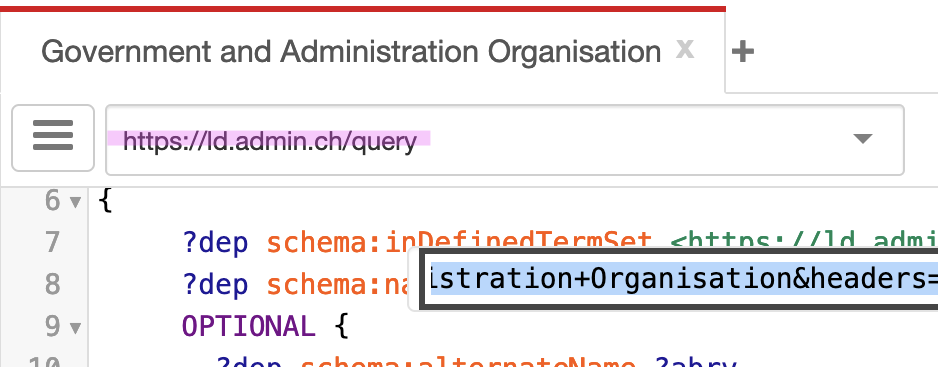
So when we want to run the query directly via HTTP, we need to send it to https://ld.admin.ch/query.
Content-types
RDF & SPARQL make heavy use of an HTTP concept called content negotiation (opens new window). This is a very powerful concept but surprisingly few developers heard about it. SPARQL gives you a choice in what way you can get the answer. Depending on your preferences and/or programming environment, one or the other is used.
In SPARQL 1.1, SPARQL-SELECT queries can be returned as:
- Text, in CSV format (or TSV, see spec below). Content-Type:
text/csv - JSON. Content-Type:
application/sparql-results+json - XML. Content-Type:
application/sparql-results+xml
If you come from a relational DB background, the answers look like a result set containing columns/keys per variables used in the SELECT-clause. But what do I choose now?
- When I want to do something simple or just look at the results in my console or editor, I use the text format.
- I rarely use JSON myself as it is not particularly nice to read. However, probably almost all libraries in the JavaScript world request that format.
- I use XML when the result is another XML consumer. This could be XSLT converting it to a more "XML-like" tree structure or a library/API/bus that expects XML as input.
You only have to worry about content-types in case you don't use a library and I would advise strongly against that. Find a library for your programming language and let it take care of it, so you can focus on the results instead!
Running curl
We now know how to encode the query, we know what we want (CSV as content-type) and we figured out where to send it (our endpoint). Let's execute a SPARQL query in our shell using curl! As an example, we take a query that queries Swiss Government and Administration Organisations (opens new window). Copy the query itself in a file with the extension .rq, which is the most commonly used file extension for SPARQL.
Once you did that, you can run the query via curl:
curl -H "Accept: text/csv" --data-urlencode query@sparql-query.rq https://ld.admin.ch/query -o swiss-offices.csv
The -H "Accept: text/csv" sets the requested content-type to CSV, --data-urlencode query@sparql-query.rq uri-encodes the query and sends it to query on the endpoint, according to the SPARQL 1.1 Protocol. If you don't want to save it to a file, simply omit the -o swiss-offices.csv option and curl will echo the result on stdout.

Using Postman
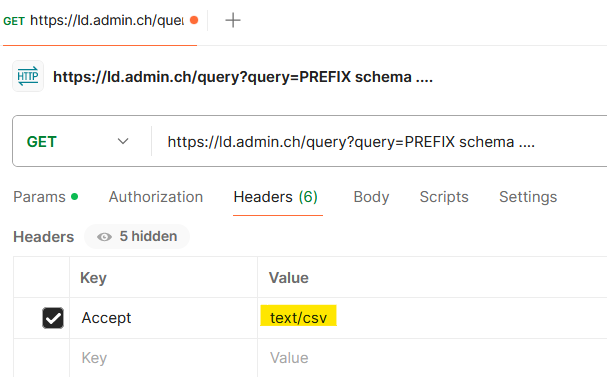
Postman is a popular alternative to curl for those who prefer graphical user interfaces. We can enter the endpoint (the part highlighted in yellow in the screenshot below) in the text box for a GET request, and separately insert SPARQL text as the value of a query parameter named query:
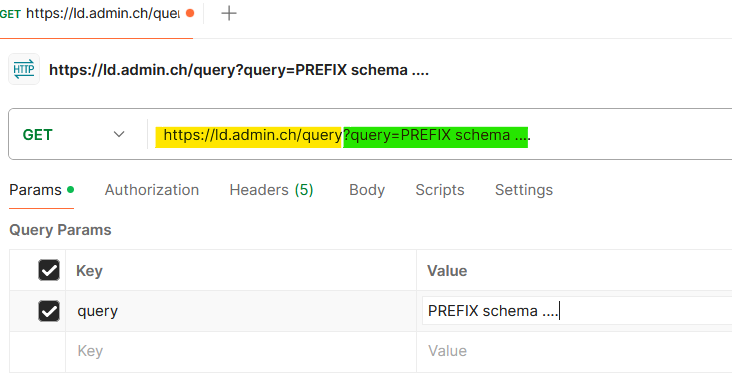
The escaped text of the query (the part highlighted in green in the screenshot above) will be automatically appended to the request. Before sending, we can optionally set our preferred result format by adding a proper Accept header:
Libraries in programming languages
In many programming languages, there are libraries available to execute SPARQL queries and iterate on the result. Many languages also provide SPARQL builders but they are outside the scope of this article.
If you would like to recommend other libraries, please let us know.
JavaScript
- sparql-http-client (opens new window), a SPARQL client for easier handling of SPARQL Queries and Graph Store requests.
- d3-sparql (opens new window), a library that creates a simple
d3-csvlike JSON data structure fromSELECT-queries.
Python
- SPARQLWrapper (opens new window) is a simple Python wrapper around a SPARQL service to remotely execute your queries.
Java
Apache Jena
Eclipse RDF4J
.NET
- dotnetrdf (opens new window) SPARQL query interface.
Rust
- Sparesults (opens new window), a set of parsers and serializers for SPARQL query result formats. There is still some glue code needed for the request itself. The author plans to provide a standalone client soon.
Elixir
- SPARQL.ex (opens new window), which contains a generic client
SPARQL.client
R
- R & SPARQL (opens new window), detailed blog post how SPARQL can be executed within R-Markdown.
Learning SPARQL & Support
If you are completely new to SPARQL and want to do more than just execute other people's queries, I would recommend O'Reillys Learning SPARQL (opens new window) book. There are other good tutorials out there, among others:
- Wikidata (opens new window) SPARQL Tutorial
- Stardog (opens new window) Tutorial
I use the W3C specs regularly to look up stuff, they are well written in my opinion. If you get stuck, check out Stackoverflow (opens new window) as well, many very skilled people answer SPARQL related questions there.
There is also a Github Discussion (opens new window) community available where you might post questions.
SPARQL specification
For this post, the following SPARQL specifications are relevant:
- SPARQL 1.1 Query Language (opens new window): The query language itself (read-only)
- SPARQL 1.1 Query Results: Different types of query results that can be requested
- SPARQL 1.1 Protocol (opens new window): The HTTP operations used to run SPARQL queries
If you want to write data, SPARQL 1.1 Update (opens new window) or SPARQL 1.1 Graph Store HTTP Protocol (opens new window) are the relevant specifications but they are not covered here.